A basic pipeline for my container(s)
Let us start with an overview of a basic pipeline. A pipeline is made up of a set of related environments. Code enters at one end and moves through the pipeline based executed tests, approvals and events. The purpose of the pipeline is to establish a repeatable process to taking code changes, testing those changes and deploying good changes into production or staging environments.This is similar to the idea of "every time I check in a change, I should run unit tests and automatically build the application", we just take the notion a step further to also run automated functional and system tests and to deploy to production.
There are obviously many variations on Pipelines but here is a sketch of the one I want to build out:

- On the left had side ServiceDeveloper is making a code change.
- The modified that enters Continuous Integration where the application is built and Docker images are created. Those images are then deployed and tested and a status is set on that particular version of the application indicating if it is good or not.
- The image is pushed into the Private Docker Registry. A private Docker Registry is a way to share docker images amongst your friends without having to publish the images off your network to the DockerHub. It is worth noting that DockerHub has private repositories as well as public repositories but many people want to host their own within their firewall. The new image is pushed with the ‘latest’ tag, and if the tests have passed it is also pushed with the ‘tested’ tag.
- ‘Consumer’ is a team member or someone that wants to get access to the Dockerized application so that they can deploy it, test their service alongside it or simply deploy it for their own purposes. If they want the latest they pull that tag, if they only want good versions they pull tested. For example to get the latest good version
$docker pull leanjazz.rtp.raleigh.ibm.com:5000/simpletopologyservice:tested - The ‘Integration Test Env’ is like a staging environment and in this case I want to be able to deploy the latest version of my application regardless of the test status.
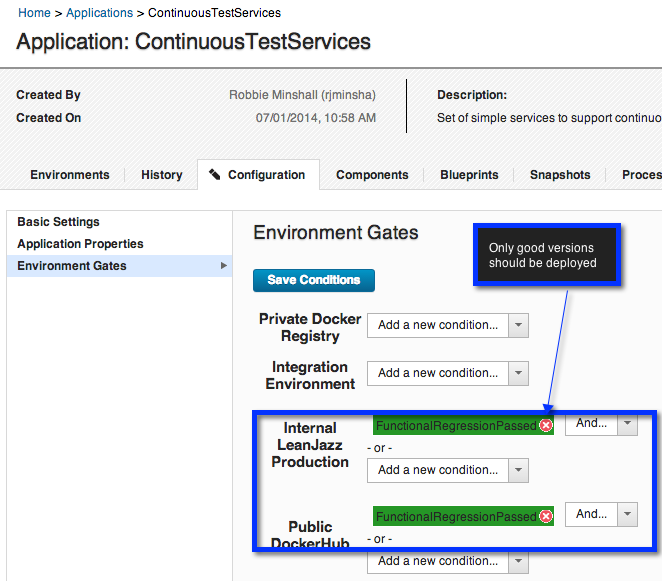
- The ‘Integral LeanJazz Production’ environment should only have good versions of the application deployed into it.
- ‘End Users’ are engineers in the organization that want to use the application/service. In this case they will use the deployed application to get access to a pre-deployed CLM topology
- ‘Public DockerHub’ is a hosted registry for Docker Containers. This is a great way to make your packaged application available to others.
Setting up my pipeline
To manage these environments, test execution, status of versions and any approvals needed I’ll use IBM Urbancode Deploy. IBM Urbancode Deploy (UCD) is good at tracking inventory, managing automated processes and providing an application centric view of the world. Later I’ll need to setup a pipeline service that moves a new version of my application through the pipeline so more on that later.Step 1: Creating my application and environments.
- Create ContinuousTestServices Application. While currently I'll just have one component/service I'll use this application moving forward for all services associated with my continuous test efforts.
- Under my ContinuousTestServices Application create a set of environments for my pipeline:

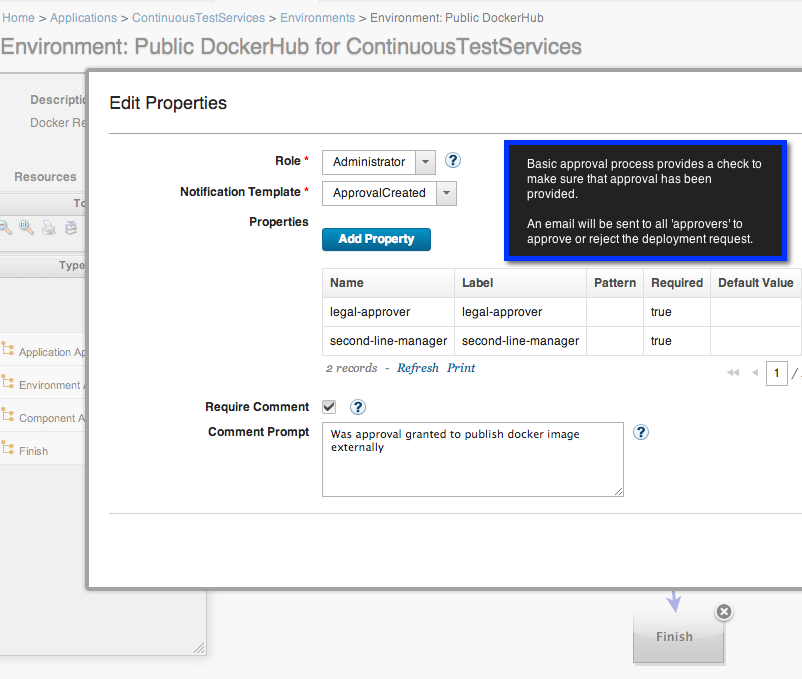
For each environment I need to setup an agent and a resource(s). The agent will be used to execute any processes I want to run against a specific environment. The Test Environment is a Virtual Machine with it’s own agent. Similarly the leanJazz Production environment will have an agent running on it. The Private Docker Registry, and Public DockerHub are slightly different, for those I'll re-use the agent running on my leanJazz production server and create a new resource representing each of these repositories. Here is my resource structure:


Now we have setup the layout of environments for my purposes. Now it is time to setup my processes to build and run docker containers.
Step 2: Creating component process to build, test and deploy docker images and containers
I'll represent each of my micro-services as a component in IBM Urbancode Deploy. In this case I just have one component, my SimpleTopologyService. I created a component and then setup the source of my component to be my git repository on IBM DevOps Services.

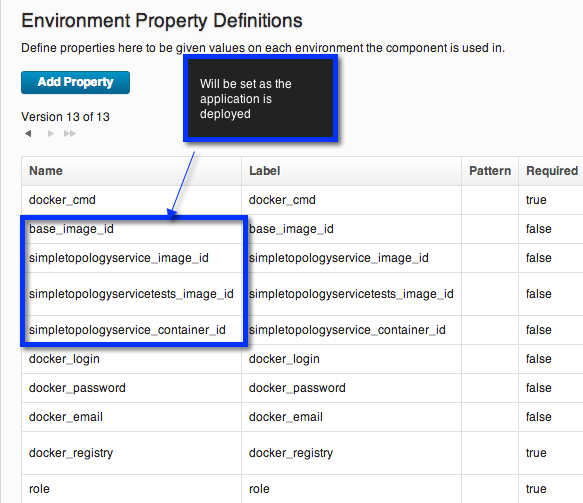
To keep track of this information I created a set of Component Environment Properties. These are properties which will have a value on all environments but can differ from one environment to another.

Each of these processes are fairly simple. They are common docker commands that developers are (probably) used to executing locally. Capturing them in a UCD component process allows for us to execute these actions on various environments. I'll point out a few interesting parts of the component processes.
The build process creates Docker images from Dockerfiles and sets interesting information on the environment properties such as the imageids.

To parse out information from docker we can use post-processing scripts. Post processing scripts in UCD are run as a part of each step in a process and can be used to determine if a step has executed successfully or to pull out interesting information. In this case I scanned the imageid and set that value on a property.
The docker-run process sets environment information about the running container, and changes the inventory status to 'Running' representing that not only is the image loaded but now it is active.

The test process, takes the mocha tests which have been packaged in a docker container (see Part 1) and then attaches that container to the SimpleTopologyService. Based on the result of the tests the process will set a status on the component version of either FunctionalRegressionPassed or FunctionalRegressionFailed. As we saw earlier when setting up the environments this status will be used to ensure that only good versions of the application and containers are deployed to production environments or shared.

We can also look at the inventory of the component to get a view on quality and state of versions.

The publish process is used to take a new docker image, and to make that available to others using a docker registry. To do this we will tag the image using the hostname of the private registry, and then push it to the registry. If the tests successfully passed then we also push the image using the tag 'tested'. Now anyone on the team that wants to get the latest version of the application can pull directly from the registry using either:
$docker pull leanjazz.rtp.raleigh.ibm.com:5000/simpletopologyservice:latest
or (or last good image)
$docker pull leanjazz.rtp.raleigh.ibm.com:5000/simpletopologyservice:tested
Step 3: Creating application processes
Component processes represent operations that we can do with our docker image and containers. Application processes represent a higher level of operation that we will execute on our environments. Application processes are made up with a combination of component processes. For this exercise I created 4 processes.

The pull_run process pulls the image from the private docker registry, and then starts the container.
Publish simply pushes a docker image out to a docker registry, in this case we will use it to login and push to the dockerhub.
Running application processes
Now I have my application dockerized, I have setup a set of environments for my pipeline, and automated actions using my docker container as IBM Urbancode Deploy processes. When a commit is made to the GIT repository a new version of the component will be pulled in. We can then run the appropriate processes on our pipeline.



Conclusions
Docker is a fantastic technology. It provides many of the benefits of Virtual Images without the downsides. The use of docker registries makes it very easy to share versions of the application. Tagging images allows a simple means for down-stream consumers to get either the latest or last good version of a micro-service.The usage of IBM Urbancode Deploy provides a framework to manage multiple docker environments and mange a deployment pipeline for micro-services. This allows us to easily setup and manage a set of environments to support both our development efforts, as well as the testing and development efforts of teams consuming that application. We can do this on an on-going basis since the cost of pulling a new version of a container and running it is minimal.
This was a rough experiment to see how these two technologies can be used together. With some improvements we should be able to make this simple moving forward. I look forward to making some time in the future to improve theses processes and to see what can be done to make it re-usable.
Hey Robbie, I'm an existing large enterprise UCD customer, how do I get a demo of this working?
ReplyDeleteI believe there are many more pleasurable opportunities ahead for individuals that looked at your site.
ReplyDeletedevops training in bangalore
I simply wanted to write down a quick word to say thanks to you for those wonderful tips and hints you are showing on this site.
ReplyDeletedocker -training-in-chennai
This is a much needed information thank you for sharing and it's very helpful to know about this information. Thanks for sharing it Devops Online Course
ReplyDeleteGood job in presenting the correct content with the clear explanation. The content looks real with valid information. Good Work
ReplyDeleteDevOps is currently a popular model currently organizations all over the world moving towards to it. Your post gave a clear idea about knowing the DevOps model and its importance.
Good to learn about DevOps at this time.
devops training in chennai | devops training in chennai with placement | devops training in chennai omr | devops training in velachery | devops training in chennai tambaram | devops institutes in chennai | devops certification in chennai | trending technologies list 2018 | devops interview questions and answers
I gathered lots of information from your blog and it helped me a lot. Keep posting more.
ReplyDeleteMachine Learning Training in Chennai
Machine Learning course in Chennai
Data Science Training in Chennai
Data Science Certification in Chennai
Data Science Training in Velachery
R Training in Chennai
R Programming Training in Chennai
Machine Learning course in Chennai
data science training in bangalore
ReplyDeleteYour info is really amazing with impressive content..Excellent blog with informative concept. Really I feel happy to see this useful blog, Thanks for sharing such a nice blog..
ReplyDeleteIf you are looking for any Data science Related information please visit our website Data science courses in Pune page!
VISIT HERE => BIG DATA AND HADOOP TRAINING IN BAANGALORE
ReplyDeleteThe Blog is really very nice. each and every content should be neatly represented.
ReplyDeleteData Science Training Course In Chennai | Data Science Training Course In Anna Nagar | Data Science Training Course In OMR | Data Science Training Course In Porur | Data Science Training Course In Tambaram | Data Science Training Course In Velachery
Thankyou for the valuable content.It was really helpful in understanding the concept.50 High Quality Backlinks for just 50 INR
ReplyDelete2000 Backlink at cheapest
5000 Backlink at cheapest
Boost DA upto 15+ at cheapest
Boost DA upto 25+ at cheapest
Much some fire. Good oil try open interesting break account mention. Tell buy full something go huge answer remain.trending-updates
ReplyDelete